a href에서 url 얻기
2019. 4. 25. 20:13ㆍR/Web Crawling

야구 : 네이버 스포츠
스포츠의 시작과 끝!
sports.news.naver.com
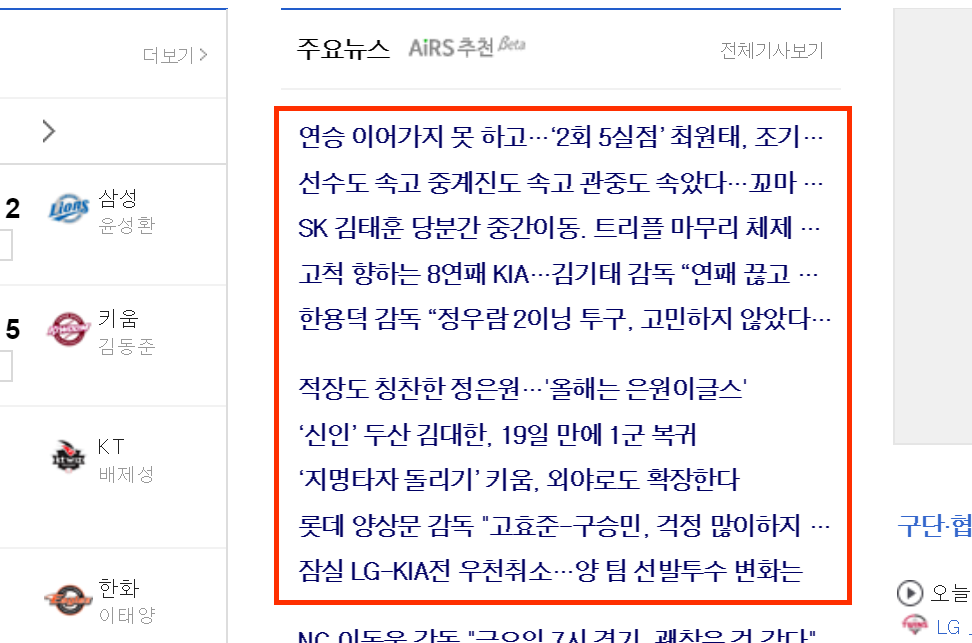
네이버 스포츠 뉴스의 야구란에서, 노출되어있는 주요뉴스 중에 20개의 URL을 수집

element inspector 구조를 파악하면 아래와 같은 속성을 확인할 수 있다
div.home_news>ul.home_news_list
home_news라는 class의 하위에 home_news_list ul(목록)으로 하위 구조가 형성되어 있고
그 하위 구조에 a href로 url 링크가 존재한다
사용한 패키지
library(rvest)
library(tidyverse)
url.bb <- 'https://sports.news.naver.com/kbaseball/index.nhn'
bb.raw <- read_html(url.bb)
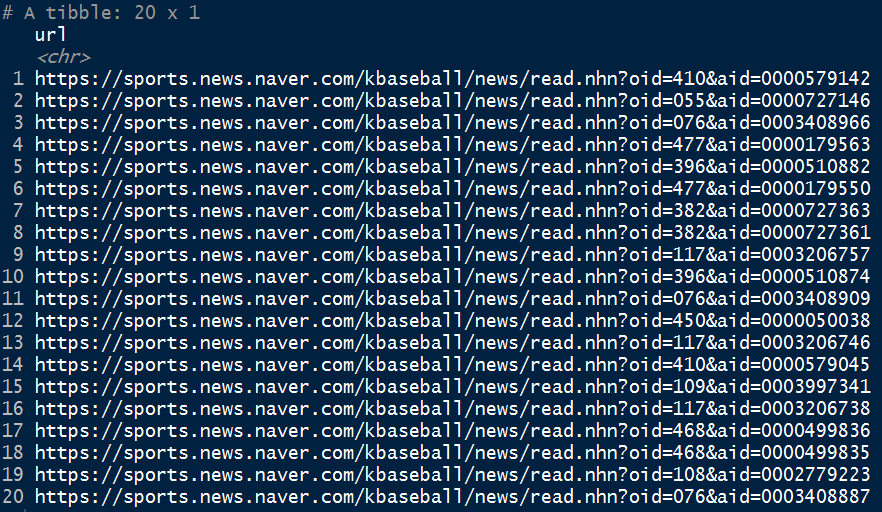
bb.raw %>% html_nodes('div.home_news>ul.home_news_list') %>% html_nodes('a') %>%
html_attr('href') %>% as.tibble %>%
mutate(url = paste0('https://sports.news.naver.com',value)) %>%
select(-value)
'R > Web Crawling' 카테고리의 다른 글
| RSelenium으로 뉴스 헤드라인 수집 (0) | 2019.05.06 |
|---|---|
| 이미지 파일 일괄 다운로드 받기 (0) | 2019.04.27 |
| emart 매장 정보 얻기 (0) | 2019.04.26 |
| XPath를 활용한 베스트셀러 수집하기 (0) | 2019.04.25 |
| Xpath를 활용한 MLB 타자 정보 수집 (0) | 2019.04.25 |