이미지 파일 일괄 다운로드 받기
2019. 4. 27. 22:19ㆍR/Web Crawling

웹에서 규칙성 있게 배치되어 있는 이미지를 한 번에 받아보자
네이버 스포츠의 현장 사진집에는 수십장의 사진이 올라가 있다
손으로 하나씩 다운로드 하려면 상당히 번거로운 작업이 기다리고 있다
국내야구, 생생화보, 포토센터 : 네이버 스포츠
롯데! 이겼다!
sports.news.naver.com
한 페이지에 20장 씩, 총 3페이지로 구성되어 있다
규칙성을 찾아 보자

https://sports.news.naver.com/photocenter/photoList.nhn?category=kbo&type=theme&page=2&albumId=73412
앨범은 총 3페이지로 구성되어 있고, URL에서 하이라이트되어 있는 숫자가 1~3으로 변한다


//*[@id="content"]/div/div[1]/div/ul/li[1]/p/a
//*[@id="content"]/div/div[1]/div/ul/li[20]/p/a
페이지 안에서는 li의 숫자가 1~20으로 변한다
<################################
################################
## get baseball pictures
################################
################################
################################
## get urls
################################
# url & xpath
naver.url <- 'https://sports.news.naver.com'
kbo.url.raw <- 'https://sports.news.naver.com/photocenter/photoList.nhn?category=kbo&type=theme&page='
#1&albumId=73412'
xpath.raw <- '//*[@id="content"]/div/div[1]/div/ul/li['# 1]/p/a
# url.collector
pic.urls <- matrix(nrow = 60, ncol = 1) %>% as.tibble
pic.urls
for(p in 1:3){
# 1~3 pages
kbo.url <- paste0(kbo.url.raw, p, '&albumId=73412')
parsed <- read_html(kbo.url)
for(i in seq(20)){
# urls
xpath <- paste0(xpath.raw, i, ']/p/a')
pic.urls[(20*(p-1)+i),1] <- parsed %>% html_nodes(xpath = xpath) %>%
html_attr('href') %>% as.tibble %>% separate(value, c("a"),sep = '"')
}
}
pic.urls <- pic.urls %>% filter(!is.na(V1)) %>%
mutate(url = paste0(naver.url,V1)) %>% select(url)
pic.urls %>% as.data.frame()
총 52 페이지의 URL 수집 성공
################################
## get pics
################################
title.merged <- matrix(nrow = 60, ncol = 3) %>% as.tibble %>% rename(num = V1, title = V2, down.url = V3)
title.merged
for(i in seq(60)){
url2nd <- pic.urls[i,1] %>% toString()
parsed2 <- read_html(url2nd)
title.merged[i,1] <- i
title.merged[i,2] <- parsed2 %>%
html_nodes(xpath = '//*[@id="photo_article"]/h2') %>%
html_text() %>% str_trim(side = c("both")) %>%
str_replace_all('[^a-zA-Z0-9가-힇]*', '_')
title.merged[i,3] <- parsed2 %>% html_nodes(xpath = '//*[@id="news_content"]/span/table/tbody/tr/td/table/tbody/tr/td/table/tbody/tr/td[2]/img') %>% html_attr('src')
}
title.merged <- title.merged %>% filter(!is.na(down.url)) %>%
mutate(num.title = paste0(num,title)) %>% select(num.title,down.url)
title.merged

다운로드 url과 파일명의 데이터프레임(tibble)을 생성
※ 파일명이 중복될 경우 덮어씌우기 때문에, 제목 앞에 숫자로 순서를 표시
for(i in seq(length(title.merged$title))){
download.file(title.merged$down.url[i],
paste0('./lotte_vs_kia/', title.merged$num.title[i],'.jpg'),
mode = 'wb')
}
download.file 함수를 사용하면 웹에서 파일을 직접 다운로드 받을 수 있다
-
download.file( [url], [경로+파일명], mode = 'wb)

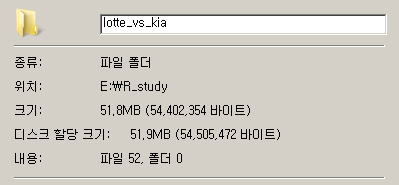
52개의 파일을 성공적으로 다운로드
'R > Web Crawling' 카테고리의 다른 글
| RSelenium으로 뉴스 헤드라인 수집 (0) | 2019.05.06 |
|---|---|
| emart 매장 정보 얻기 (0) | 2019.04.26 |
| a href에서 url 얻기 (0) | 2019.04.25 |
| XPath를 활용한 베스트셀러 수집하기 (0) | 2019.04.25 |
| Xpath를 활용한 MLB 타자 정보 수집 (0) | 2019.04.25 |