2019. 4. 25. 12:44ㆍR/Web Crawling

RIDIBOOKS
최고의 eBook 서비스, 리디북스! 200만 권의 eBook, 특별반값 도서, 최신 베스트셀러에서 빌려보는 만화/판무/잡지, 내 문서파일 (PDF/TXT/ePub) 뷰어 기능까지!
ridibooks.com
리디 북스의 월간 베스트 셀러 Top30을 수집
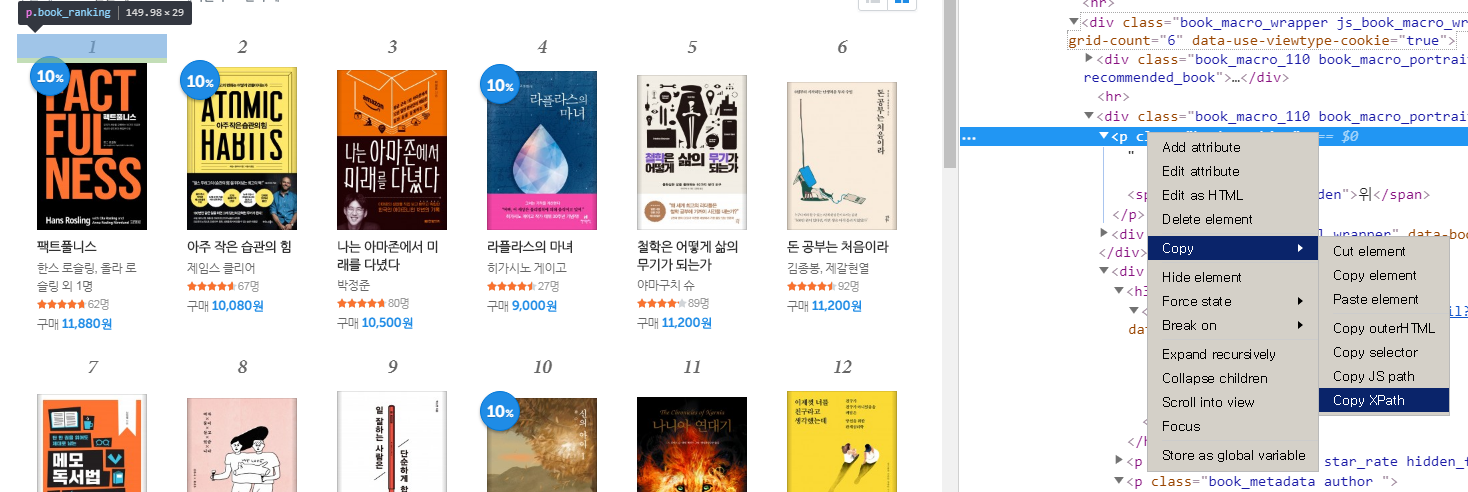
베스트 셀러는 [순위], [제목], [작가], [가격] 등의 정보가 기제되어 있다.
순위, 제목, 작가, 가격에 대하여 xpath 규칙성을 파악한다
# 순위 규칙
//*[@id="page_best"]/div[2]/div[2]/p
//*[@id="page_best"]/div[2]/div[3]/p
//*[@id="page_best"]/div[2]/div[31]/p
# 제목 규칙
//*[@id="page_best"]/div[2]/div[2]/div[2]/h3/a/span
//*[@id="page_best"]/div[2]/div[31]/div[2]/h3/a/span
# 작가 규칙
//*[@id="page_best"]/div[2]/div[2]/div[2]/h3/a/span
# 가격 규칙
//*[@id="page_best"]/div[2]/div[2]/div[2]/div/p/span[1]/span
규칙 확인 결과 2 번째 div의 숫자가 2에서 31까지 변동하는 것을 알 수 있다.
위 규칙을 바탕으로 4열 30행의 매트릭스에 정보를 수집하는 함수를 제작한다
rd.url <- 'https://ridibooks.com/bestsellers/general?order=monthly'
rd <- read_html(rd.url)
get.bestseller.ridi <- function(html){
# xpath 규칙 설정을 위한 준비
xpath.rank <- '//*[@id="page_best"]/div[2]/div[' #2]/p
xpath.title <- '//*[@id="page_best"]/div[2]/div[' #2]/div[2]/h3/a/span
xpath.arthur <- '//*[@id="page_best"]/div[2]/div[' #2]/div[2]/h3/a/span
xpath.price <- '//*[@id="page_best"]/div[2]/div[' #2]/div[2]/div/p/span[1]/span
# 4x30 매트릭스 생성
raw.data <- matrix(ncol = 4, nrow =30 )
colnames(raw.data) <- c("rank", "title", "arthrur", "price")
raw.data
# 4x30 매트릭스에 반복문으로 정보를 기입
for(i in 1:30){
k = i + 1
xpath.rank2 <- paste0(xpath.rank, k, ']/p')
xpath.title2 <- paste0(xpath.title, k, ']/div[2]/h3/a/span')
xpath.arthur2 <- paste0(xpath.arthur, k, ']/div[2]/h3/a/span')
xpath.price2 <- paste0(xpath.price, k, ']/div[2]/div/p/span[1]/span')
raw.data[i,1] <- html %>% html_node(xpath = xpath.rank2) %>%
html_text() %>% str_replace_all("\\n", "") %>% str_replace_all("\\s{2,}","")
raw.data[i,2] <- html %>% html_node(xpath = xpath.title2) %>%
html_text() %>% str_replace_all("\\n", "") %>% str_replace_all("\\s{2,}","")
raw.data[i,3] <- html %>% html_node(xpath = xpath.arthur2) %>%
html_text() %>% str_replace_all("\\n", "") %>% str_replace_all("\\s{2,}","")
raw.data[i,4] <- html %>% html_node(xpath = xpath.price2) %>%
html_text() %>% str_replace_all("\\n", "") %>% str_replace_all("\\s{2,}","")
}
ridi.best <- raw.data %>% as.tibble %>% View
}
get.bestseller.ridi(rd)


두 정보가 일치하는 것을 확인할 수 있다
'R > Web Crawling' 카테고리의 다른 글
| RSelenium으로 뉴스 헤드라인 수집 (0) | 2019.05.06 |
|---|---|
| 이미지 파일 일괄 다운로드 받기 (0) | 2019.04.27 |
| emart 매장 정보 얻기 (0) | 2019.04.26 |
| a href에서 url 얻기 (0) | 2019.04.25 |
| Xpath를 활용한 MLB 타자 정보 수집 (0) | 2019.04.25 |