2019. 4. 25. 11:04ㆍR/Web Crawling

2019 Major League Baseball Season Summary | Baseball-Reference.com
2019 MLB Standings, Team and Player Statistics, Leaderboards, Award Winners, Trades, Minor Leagues, Fielding, Batting, Pitching, New Debuts
www.baseball-reference.com
MLB의 팀별 타자 정보를 데이터 형태로 가져와보자
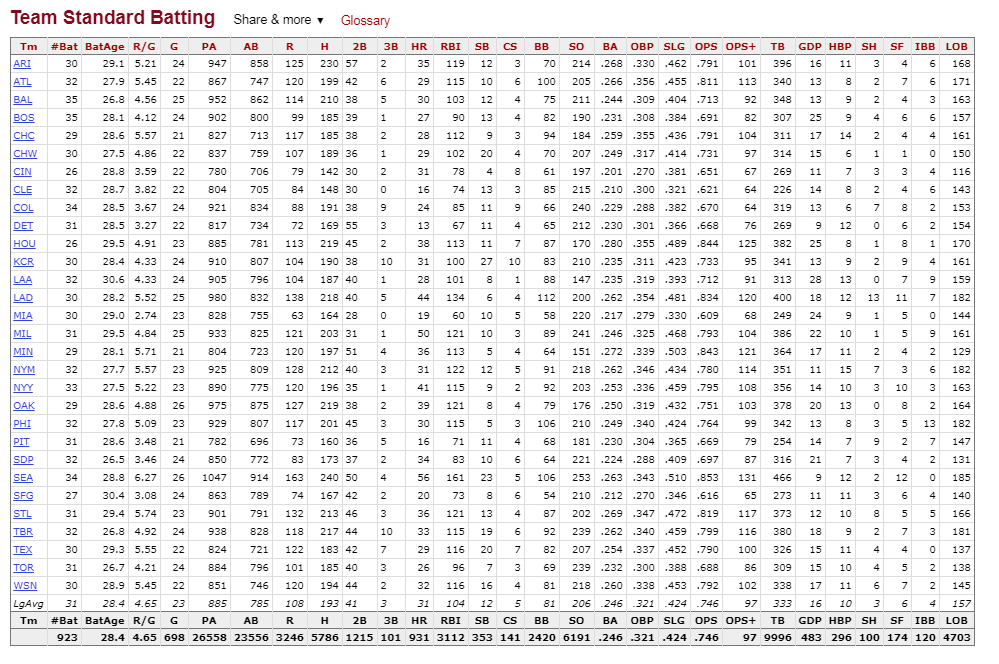
팀별 타격 데이터는 테이블 형태로정리되어 있다
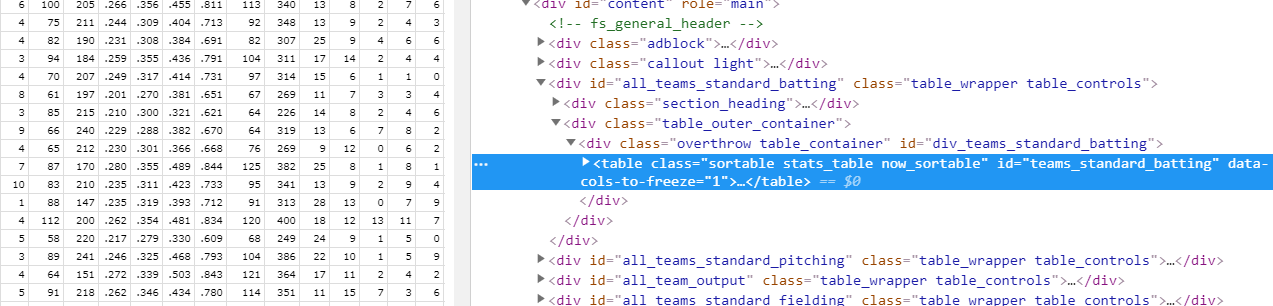
element inspector로 확인해보면 데이터 테이블의 id가 div_teams_standard_batting인 것을 알 수 있다
url.mlb <- 'https://www.baseball-reference.com/leagues/MLB/2019.shtml'
mlb.raw <- read_html(url.mlb)
mlb.raw %>% html_node('#div_teams_standard_batting') %>% html_text()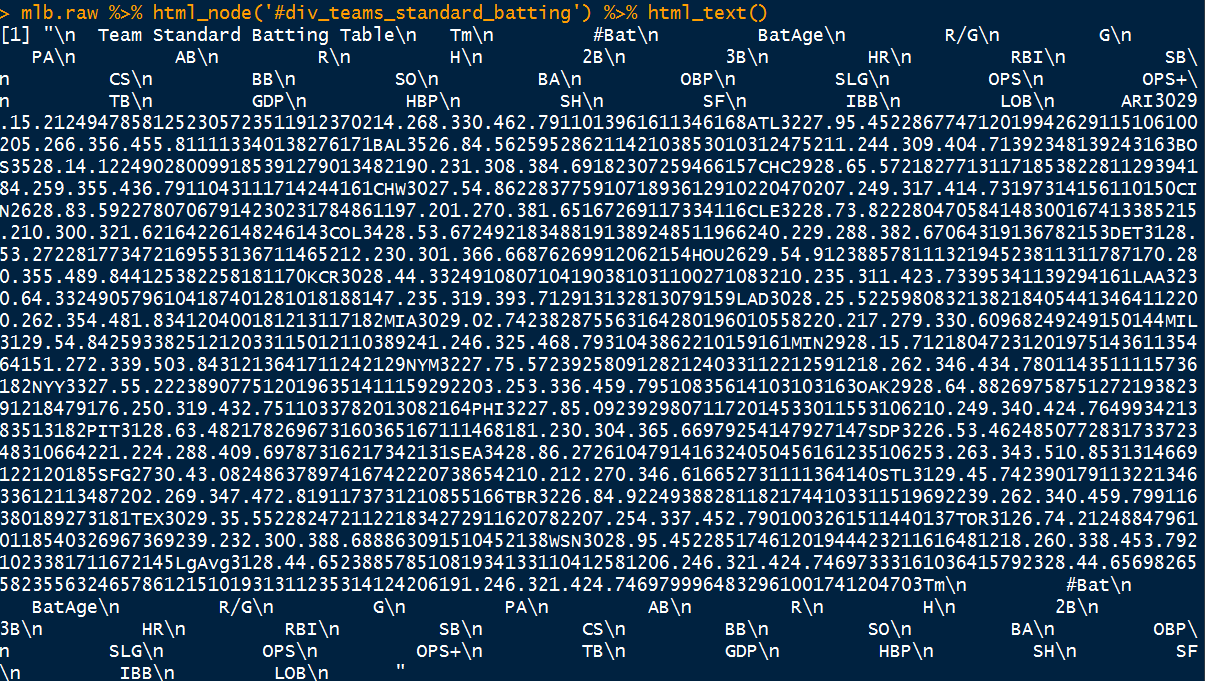
결과물을 보면 테이블이 깨져서 나온다.
규칙성을 찾기도 힘들어서 데이터를 분리할 수도 없기에 다른 규칙성을 찾아봐야 한다

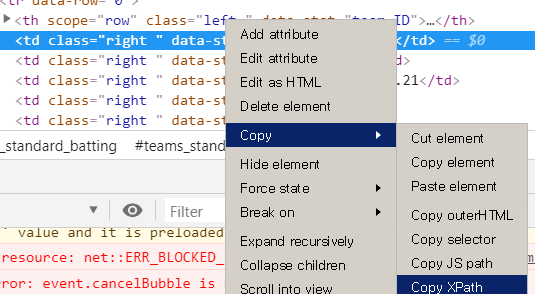
XPath를 사용해 보자
테이블의 셀 하나를 클릭한 후 XPath들을 확인해보면 아래와 같다
//*[@id="teams_standard_batting"]/thead/tr/th[1]
데이터 최상단의 헤드 부분이다. th가 1에서 29까지 column 형태로 존재
//*[@id="teams_standard_batting"]/tbody[1]/tr[1]/th
데이터 최좌측의 팀명 부분이다. tr이 1에서 31까지 row형태로 존재
//*[@id="teams_standard_batting"]/tbody[1]/tr[1]/td[1]
//*[@id="teams_standard_batting"]/tbody[1]/tr[31]/td[28]
타격 데이터 부분이다. tr이 row, td가 columb의 형태로해서 28x31 행렬을 구성
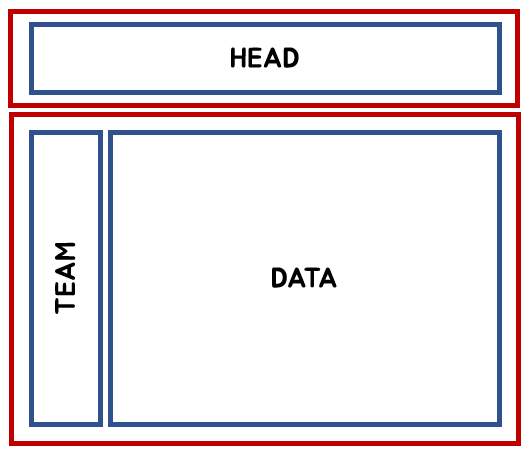
데이터 매트릭스 구성을 위한 기본 아이디어는 다음과 같다
-
Head : 테이블의 Head를 수집하여 colnames로 삽입
-
Team : 팀명을 row 형태로 수집
-
Data : 타격 데이터를 matrix 형태로 수집
-
Team + Data → bind row
사용한 패키지
library(rvest)
library(tidyverse)
library(XML)
library(httr)
XML의 xpathapply를 사용한 케이스
url.mlb <- 'https://www.baseball-reference.com/leagues/MLB/2019.shtml'
#################################################################
############# xpath
#################################################################
library(XML)
library(httr)
mlb.raw.xpath <- GET(url.mlb)
mlb.raw.xpath <- htmlParse(mlb.raw.xpath)
data.raw.xpath <- '//*[@id="teams_standard_batting"]/tbody[1]/tr['
head.raw.xpath <- '//*[@id="teams_standard_batting"]/thead/tr/th['
get.mlb.hit.data(mlb.raw.xpath)
get.mlb.hit.data <- function(x){
raw.head <- matrix(nrow = 1, ncol = 29)
raw.data <- matrix(nrow = 31, ncol = 29)
## get header
for(i in 1:29){
head.team.xpath <- paste0(head.raw.xpath,i,']')
raw.head[i] <- xpathApply(mlb.raw.xpath, head.team.xpath, xmlValue) %>% unlist()
}
## get data
k <- NULL
for(i in 1:31){
for(j in 1:29){
k <- j - 1
team.temp.xpath <- paste0(data.raw.xpath,i,']/th')
data.temp.xpath <- paste0(data.raw.xpath,i,']/td[',k,']')
if(j == 1){
raw.data[i,j] <- xpathApply(mlb.raw.xpath, team.temp.xpath, xmlValue) %>% unlist()
} else {
raw.data[i,j] <- xpathApply(mlb.raw.xpath, data.temp.xpath, xmlValue) %>% unlist()
}
}
}
raw.head <- as.tibble(raw.head)
raw.data <- as.tibble(raw.data)
names(raw.data) <- raw.head
mlb.hitting <- raw.data
View(mlb.hitting)
}
rvest의 html_node 활용한 케이스
#################################################################
############# rvest
#################################################################
mlb.raw.rvest <- read_html(url.mlb)
data.raw.xpath <- '//*[@id="teams_standard_batting"]/tbody[1]/tr['
head.raw.xpath <- '//*[@id="teams_standard_batting"]/thead/tr/th['
get.mlb.hit.data2 <- function(x){
raw.head <- matrix(nrow = 1, ncol = 29)
raw.data <- matrix(nrow = 31, ncol = 29)
## get header
for(i in 1:29){
head.team.xpath <- paste0(head.raw.xpath,i,']')
raw.head[i] <- html_node(x, xpath = head.team.xpath) %>% html_text()
}
## get data
k <- NULL
for(i in 1:31){
for(j in 1:29){
k <- j - 1
team.temp.xpath <- paste0(data.raw.xpath,i,']/th')
data.temp.xpath <- paste0(data.raw.xpath,i,']/td[',k,']')
if(j == 1){
raw.data[i,j] <- html_node(x, xpath = team.temp.xpath) %>% html_text()
} else {
raw.data[i,j] <- html_node(x, xpath = data.temp.xpath) %>% html_text()
}
}
}
raw.head <- as.tibble(raw.head)
raw.data <- as.tibble(raw.data)
names(raw.data) <- raw.head
mlb.hitting <- raw.data
View(mlb.hitting)
}
get.mlb.hit.data2(mlb.raw.rvest)
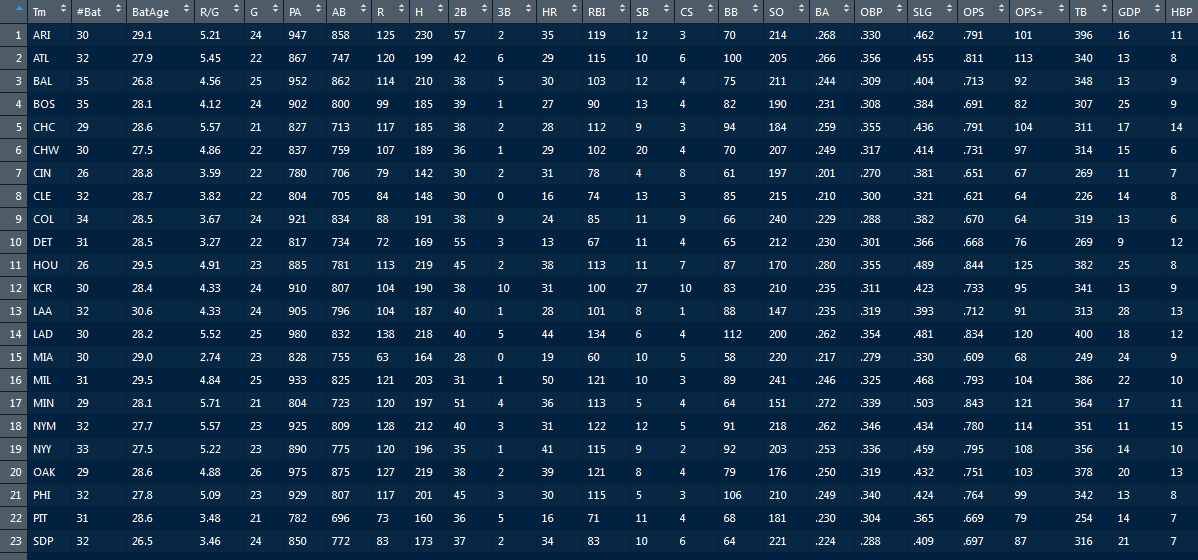
get.mlb.hit.data2(mlb.raw.rvest)를 실행 하면 아래와 같은 결과값을 얻을 수 있다
'R > Web Crawling' 카테고리의 다른 글
| RSelenium으로 뉴스 헤드라인 수집 (0) | 2019.05.06 |
|---|---|
| 이미지 파일 일괄 다운로드 받기 (0) | 2019.04.27 |
| emart 매장 정보 얻기 (0) | 2019.04.26 |
| a href에서 url 얻기 (0) | 2019.04.25 |
| XPath를 활용한 베스트셀러 수집하기 (0) | 2019.04.25 |