2019. 4. 18. 03:03ㆍR/Advanced

목적
DSR 패키지에 포함된 데이터셋으로 정돈된 데이터 연습
다른 패키지와 tidyr의 함수 대응 관계는 아래와 같다
reshape2의 melt와 dcast는 tidyr의 gather와 spread로 대체 가능하다
|
tidyr |
gather |
spread |
|
reshape2 |
melt |
cast |
|
spreadsheets |
unpivot |
pivot |
|
databases |
fold |
unfold |
사용한 패키지
library(tidyverse) library(DSR)
TB를 포함한 table1~6에서 Spread와 Gather사용
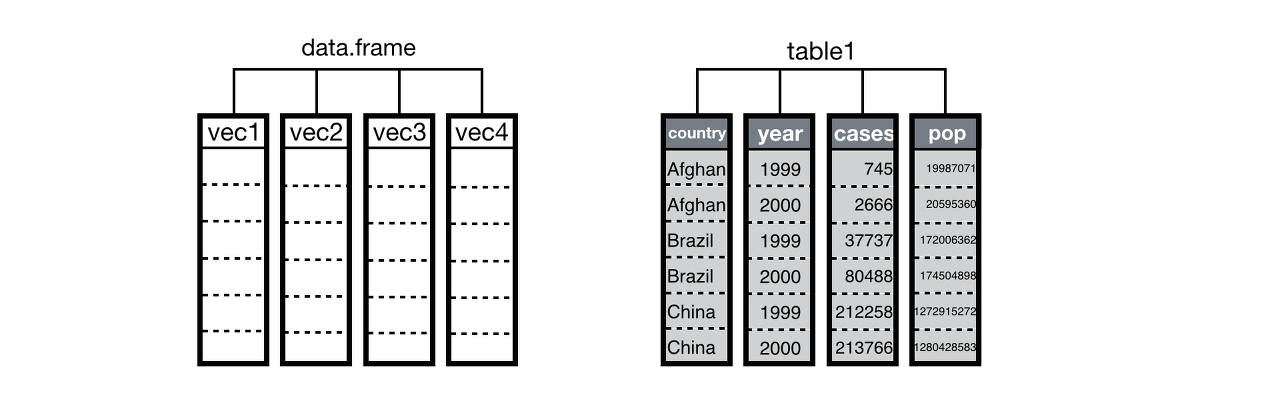
> table1 # A tibble: 6 x 4 country year cases population <fct> <int> <int> <int> 1 Afghanistan 1999 745 19987071 2 Afghanistan 2000 2666 20595360 3 Brazil 1999 37737 172006362 4 Brazil 2000 80488 174504898 5 China 1999 212258 1272915272 6 China 2000 213766 1280428583
아프가니스탄, 브라질, 중국의 1999년과 2000년의 플루 감염자와 전체 인구 데이터
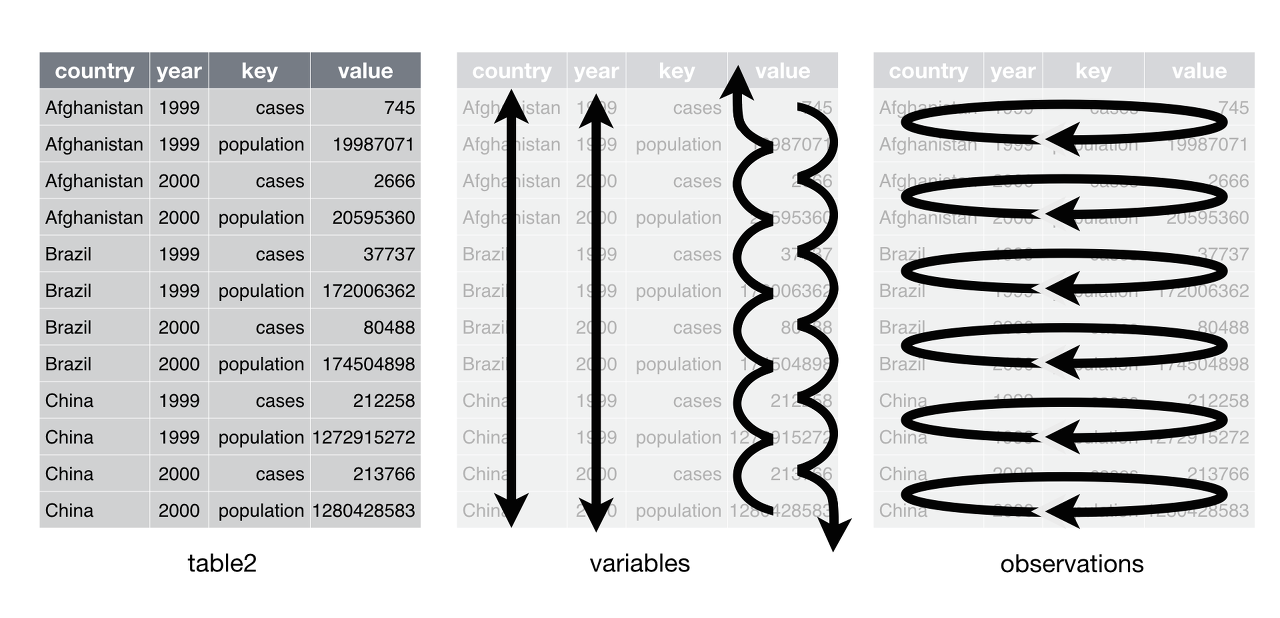
> table2 # A tibble: 12 x 4 country year key value <fct> <int> <fct> <int> 1 Afghanistan 1999 cases 745 2 Afghanistan 1999 population 19987071 3 Afghanistan 2000 cases 2666 4 Afghanistan 2000 population 20595360 5 Brazil 1999 cases 37737 6 Brazil 1999 population 172006362 7 Brazil 2000 cases 80488 8 Brazil 2000 population 174504898 9 China 1999 cases 212258 10 China 1999 population 1272915272 11 China 2000 cases 213766 12 China 2000 population 1280428583
table2는 table1의 데이터를 gather한 형태다
다시 spread로 만들어보면 아래와 같다. table1과 동일한 형식이다
> table2 %>% spread(key, value) # A tibble: 6 x 4 country year cases population <fct> <int> <int> <int> 1 Afghanistan 1999 745 19987071 2 Afghanistan 2000 2666 20595360 3 Brazil 1999 37737 172006362 4 Brazil 2000 80488 174504898 5 China 1999 212258 1272915272 6 China 2000 213766 1280428583
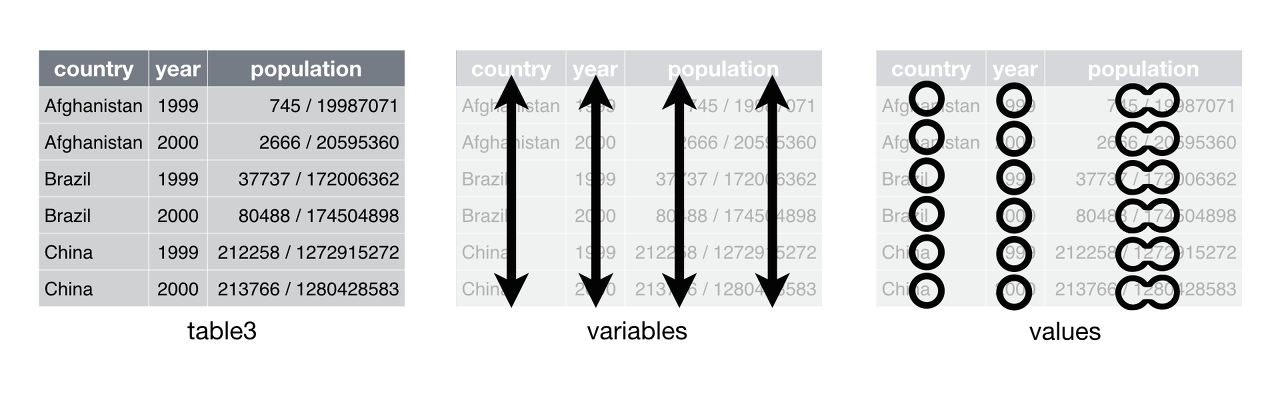
table3는 case/population의 rate라는 새로운 변수로 변경한 데이터 테이블이다
> table3 # A tibble: 6 x 3 country year rate <fct> <int> <chr> 1 Afghanistan 1999 745/19987071 2 Afghanistan 2000 2666/20595360 3 Brazil 1999 37737/172006362 4 Brazil 2000 80488/174504898 5 China 1999 212258/1272915272 6 China 2000 213766/1280428583
Separate를 사용하여 table1과 동일하게 만들 수 있다
> table3 %>% separate(rate, c("case", "population"))
# A tibble: 6 x 4
country year case population
<fct> <int> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583

table4와 table5는 case와 population을 분리해놓은 케이스다
> table4; table5 # A tibble: 3 x 3 country `1999` `2000` <fct> <int> <int> 1 Afghanistan 745 2666 2 Brazil 37737 80488 3 China 212258 213766 # A tibble: 3 x 3 country `1999` `2000` <fct> <int> <int> 1 Afghanistan 19987071 20595360 2 Brazil 172006362 174504898 3 China 1272915272 1280428583
table1 형식으로 만들기 위해서는 두 데이터를 합쳐야 한다
x <- table4 %>% gather("year", "case", 2:3)
y <- table5 %>% gather("year", "population", 2:3)
> x;y
# A tibble: 6 x 3
country year case
<fct> <chr> <int>
1 Afghanistan 1999 745
2 Brazil 1999 37737
3 China 1999 212258
4 Afghanistan 2000 2666
5 Brazil 2000 80488
6 China 2000 213766
# A tibble: 6 x 3
country year population
<fct> <chr> <int>
1 Afghanistan 1999 19987071
2 Brazil 1999 172006362
3 China 1999 1272915272
4 Afghanistan 2000 20595360
5 Brazil 2000 174504898
6 China 2000 1280428583
z <- data.frame(x, y[3])
> z
country year case population
1 Afghanistan 1999 745 19987071
2 Brazil 1999 37737 172006362
3 China 1999 212258 1272915272
4 Afghanistan 2000 2666 20595360
5 Brazil 2000 80488 174504898
6 China 2000 213766 1280428583
table6는 연도가 분리되어 있고, rate 변수가 포함되어 있다
> table6 # A tibble: 6 x 4 country century year rate <fct> <chr> <chr> <chr> 1 Afghanistan 19 99 745/19987071 2 Afghanistan 20 00 2666/20595360 3 Brazil 19 99 37737/172006362 4 Brazil 20 00 80488/174504898 5 China 19 99 212258/1272915272 6 China 20 00 213766/1280428583
unite로 연도를 합치고 rate를 separate로 분리한다
> table6 %>% unite("year", century, year, sep ="") %>%
+ separate(rate, c("case", "population"))
# A tibble: 6 x 4
country year case population
<fct> <chr> <chr> <chr>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583
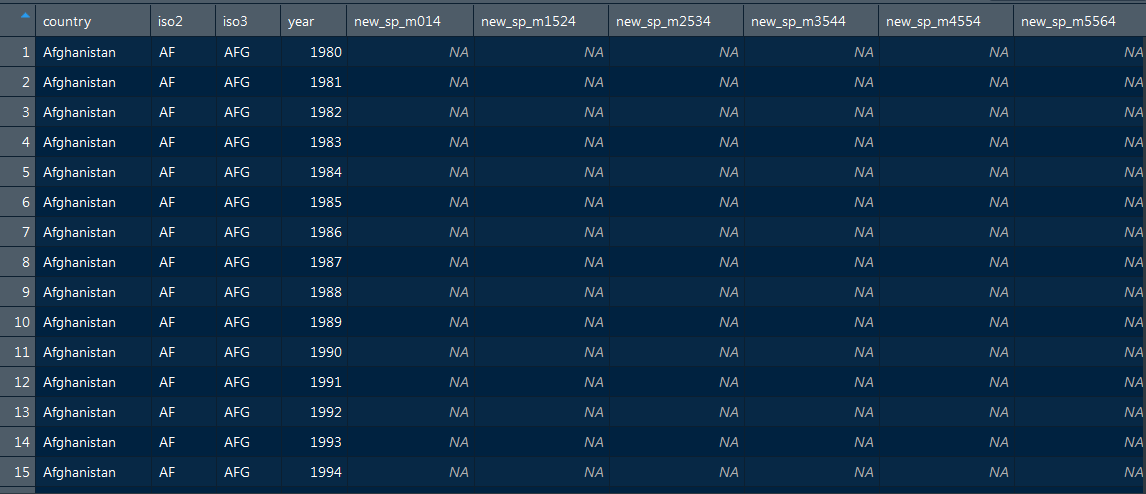
WHO 데이터 정돈하기
-
rel : 재발(relapse)
-
ep : 폐외 결핵(extrapulmonary TB)
-
sn : pulmonary smear로 검진할 수 없는 음성
-
sp : pulmonary smear로 검진할 수 있는 양성
위 데이터는 변수에 3개의 데이터가 들어가 있기 때문에 Untidy Data
Long Data로 변경한 후 변수를 분리해줘야 한다
who %>% gather("new", "value", 5:60 )

New 변수에는 SP(TB 검진 결과), 성별, 연령대가 포함되어 있다
이 변수들을 분리 해줘야 한다
who %>% gather("new", "value", 5:60 ) %>%
separate(new, c("new","type","sexage"))

sexage 변수에는 아직 성별과 연령대가 분리되지 않았다
who %>% gather("new", "value", 5:60 ) %>%
separate(new, c("new","type","sexage")) %>%
separate(sexage, c("sex", "age"), sep = 1)

연령과 성별이 완전히 분리되었다
쓸데 없는 변수를 제거해준다
who %>% gather("new", "value", 5:60 ) %>%
separate(new, c("new","type","sexage")) %>%
separate(sexage, c("sex", "age"), sep = 1) %>%
select(-country, -iso2, -new) %>%
rename(nation = iso3)
만약, 다시 데이터를 펼치고 싶다면 spread를 사용하면 된다
who %>% gather("new", "value", 5:60 ) %>%
separate(new, c("new","type","sexage")) %>%
separate(sexage, c("sex", "age"), sep = 1) %>%
select(-country, -iso2, -new) %>%
rename(nation = iso3) %>%
spread(type, value)>

'R > Advanced' 카테고리의 다른 글
| R로 텔레그램봇에 메세지 보내기 (0) | 2019.06.02 |
|---|---|
| ggmap을 사용하여 서울 지하철 역 위치 및 사용자 수 표시 (0) | 2019.05.07 |